종강하고, 인턴 서류 지원하고, 면접 보면서 느낀 점은 학교에서 배운 것들 다 중요한 cs 지식들인데 잊어버려서 배웠던 것들 정리하고, 이번에 일하게 된 곳에서 배울 파이토치랑 LLM에 대해서도 예전에 배우고, 거의 기억이 안나는 상태라, 공부를 해야겠다는 생각을 하게 되었다.
아직 시간 있고, 내년 8월에 졸업 예정이니까 시간 꽤 있으니까 지금까지 배웠던 내용 정리하면서 공부도 열심히 하자.
결론은 LLM 관련 공부 시작
이 글은 LLM을 활용한 실전 AI 애플리케이션 개발 (허정준 지음) 공부하고 쓴 글입니다.
1부. LLM의 기초 뼈대 세우기
01. LLM 지도
챗GPT : 주어진 입력에서 다음에 올 적절한 단어를 확률적으로 선택(예측)하고, 선택한 단어를 입력에 더해 문장이 끝날 때까지 선택하는 작업을 반복.
LLM은 기술적으로는 딥러닝1에 기반을 두고 있다.
LLM은 자연어 처리 분야2에 속하며, 특히 그 중에서도 사람과 비슷하게 텍스트를 생성하는 방법을 연구하는 자연어 생성에 속한다.
LLM은 다음에 올 단어가 무엇일지 예측하면서 문장을 하나씩 만들어 가는 방식으로 텍스트를 생성하는데, 이렇게 다음에 올 단어를 예측하는 모델을 언어모델 (language model) 이라고 한다.
결론 : LLM은 딥러닝 기반의 언어 모델
딥러닝 기반의 언어 모델이 지금처럼 자리 잡기까지의 중요한 역사적 사건들
2013년 워드투벡터(word2vec)
2017년 트랜스포머 아키텍처(transformer architecture)
2018년 OpenAI가 트랜스포머 아키텍처를 활용한 GPT-1 모델 공개
딥러닝과 머신러닝의 차이 : 데이터의 특징을 누가 뽑는가?
머신러닝 : 연구자 또는 개발자가 찾고 모델의 입력으로 넣어 자동차인지 아닌지 결과를 출력
딥러닝 : 모델이 스스로 데이터의 특징을 찾고 분류하는 모든 과정을 학습함

임베딩 (embedding) : 데이터의 의미와 특징을 포착해 숫자로 표현한 것
데이터는 어떻게 숫자로 변환할까? 2013년 구글에서 발표한 [Efficient Estimation of Word Representations in Vector Space] (https://arxiv.org/pdf/1301.3781) 에서 word2cve이라는 모델을 통해 단어를 임베딩으로 변환하는 방법을 소개함.
언어 모델링 : 모델이 입력받은 텍스트의 다음 단어를 예측해 텍스트를 생성하는 방식
전이 학습(transfer learning) : 하나의 문제를 해결하는 과정에서 얻은 지식과 정보를 다른 문제를 풀 때 사용하는 방식
사전 학습(pre-training) + 미세 조정(fine-tuning)
다운스트림(downstream) : 사전 학습 모델을 미세 조정해 풀고자 하는 과제
제레미 하워드(Jeremy Howard)와 세바스찬 루더(Sebastian Ruder)가 RNN에서 언어 모델링이 사전 학습 과제로 적합하다는 사실을 확인함.
대표적인 트랜스포머 모델로는 구글의 BERT(Bidirectinal Encoder Representations form Transformers)와 OPENAI의 GPT(Generative Pre-trained Transformer)가 있다.
트랜스포머가 개발되기 전에는 RNN을 활용해서 텍스트를 생성했다. RNN은 텍스트를 순차적으로 처리해서 다음 단어를 예측한다. (하나의 hidden state에 지금까지의 입력 텍스트의 맥락을 압축함)
| 장점 | 여러 단어로 구성된 맥락을 하나의 hidden state에 압축하기 때문에 메모리를 적게 사용함. 다음 단어를 예측할 때 지금까지 계산을 통해 만들어진 잠재 상태와 입력 단어만 있으면 되기 때문에 다음 단어를 빠르게 생성함. |
| 단점 | 순차적으로 입력되는 단어를 하나의 잠재 상태에 압축하다보니 먼저 입력한 단어의 의미가 점차 희석. 입력이 길어지는 경우 의미를 충분히 담지 못하고 성능이 떨어짐. |
2017년 등장한 트랜스포머 아키텍처 : 맥락을 모두 참조하는 어텐션(attention) 연산을 사용
트랜스포머 아키텍처는 맥락을 압축하지 않고 그대로 활용하기 때문에 성능을 높일 수 있지만, 입력 텍스트가 길어지면 맥락 데이터를 모두 저장하고 있어야 하기 때문에 메모리 사용량이 증가함. 또, 매번 다음 단어를 예측할 때마다 맥락 데이터를 모두 확인해야 하기 때문에 입력이 길어지면 예측에 걸리는 시간도 증가.
성능이 높아지는 대신, 무겁고 비효율적인 연산을 하게 됨.
(+ 성능과 효율성을 모두 갖춘 새롭게 등장한 모델 아키텍처 맘바? )
OPENAI 가 [Traning language models to follow instructinos with human feedback]( https://arxiv.org/pdf/2203.02155 )
논문의 연구 결과 발표와 함께 공개한 supervised fine-tuning 과 RLHF(Reinforcement Learning from Human Feedback - 사람의 피드백을 활용한 강화학습) 이라는 기술이었다. 챗GPT는 그저 사용자가 한 말 다음에 이어질 말을 생성하는 것이 아니라 사용자의 요청을 해결할 수 있는 텍스트를 생성하게 됐다.
챗gpt의 성공 이후 상업용 모델을 사용한 애플리케이션도 많았지만, 많은 기업이 자신의 조직에 특화된 sLLM을 개발하기 위해 시도했다. 대표적으로 2024년 4월 메타는 라마-3모델을 오픈소스로 공개하면서 sLLM 연구를 리드하고 있고, 구글도 2024년 6월 제미나이 개발에 사용한 기술로 만든 젬마-2 모델을 공개했다. 2024년 4월 마이크로소프트는 언어 추론 능력에 집중한 Phi-3를 공개함.Defog.ai의 SQLCoder도 있다.
LLM을 학습하고 추론할 때 GPU를 더 효율적으로 사용해 적은 GPU 자원으로도 LLM을 활용할 수 있도록 돕는 연구가 활발히 진행중.
1. 모델 파라미터를 더 적은 비트로 표현하는 양자화(quantization)
2. 모델 전체를 학습하는 것이 아니라 모델의 일부만 학습하는 LoRA(Low Rank Adaptation 방식)
LLM의 문제 "환각 현상" - 잘못된 정보나 실제로 존재하지 않는 정보를 만들어 내는 현상
해결하기 위해 RAG(검색 증강 생성 Retrieval Augmented Generation) 기술 사용 (RAG기술은 프롬프트에 LLM이 답변할 때 필요한 정보를 미리 추가함으로써 잘못된 정보를 생성하는 문제를 줄임)
02. LLM의 중추, 트랜스포머 아키텍처 살펴보기
1. 트랜스포머 아키텍처?
트랜스포머 아키텍처는 2017년 google의 Ashish Vaswani외 7인이 발표한 [Attention is All you need] 논문에서 처음 등장했다.
기존의 RNN에 비해 성능도 높고 모델 학습 속도도 빨랐다.
기존 RNN은 이전 토큰의 출력을 다시 모델에 입력으로 사용하기 때문에 입력을 병렬적으로 처리하지 못하고, 순차적으로 처리해야 하기 때문에 학습 속도가 느리고, 입력이 길어지면 먼저 입력한 토큰의 정보가 희석되면서 성능이 떨어진다는 문제가 있다. 또, 성능을 높이기 위해 층을 깊이 쌓으면 gradient vanishing이나 gradient exploding 이 발생하며 학습이 불안정해진다.
트랜스포머는 self-attention이라는 개념을 도입했다.
self-attention (셀프 어텐션) : 입력된 문장 내의 각 단어가 서로 어떤 관련이 있는지 계산해서 각 단어의 표현을 조정하는 역할을 함.
- 확장성 : 더 깊은 모델을 만들어도 학습이 잘된다. 동일한 블록을 반복해 사용하기 때문에 확장에 용이하다.
- 효율성 : 학습할 때 병렬 연산이 가능하기 때문에 학습 시간이 단축된다.
- 더 긴 입력 처리 : 입력이 길어져도 성능이 거의 떨어지지 않는다.
인코더 : 언어를 이해하는 역할
디코더 : 언어를 생성하는 역할
공통적으로 입력을 임베딩(embedding)층을 통해 숫자 집합인 임베딩으로 변환하고 위치 인코딩(positional encoding) 층에서 문장의 위치 정보를 더한다.
인코더에서는 총 정규화(layer normalization), 멀티 헤드 어텐션(multi-head attention), 피드 포워드(feed forward) 층을 거치며 영어 문장을 이해하고, 그 결과 디코더로 전달하고, 디코더에서도 인코더와 유사하게 층 정규화, 멀티 헤드 언텐션 연산을 수행하면서 크로스 어텐션 연산을 통해 인코더가 전달한 데이터를 출력과 함께 종합해서 피드 포워드 층을 거쳐 한국어 번역 결과를 생성한다.
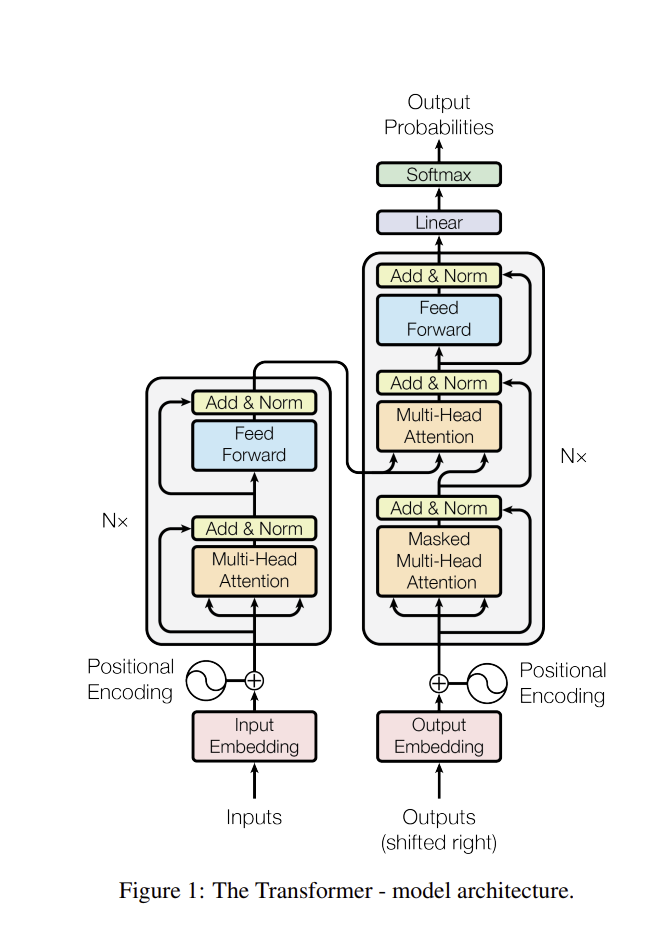
2. 텍스를 임베딩으로 변환
컴퓨터는 텍스트를 그대로 계산에 사용할 수 없기 때문에 텍스트를 숫자 형식의 데이터인 임베딩으로 변환해야 한다. 이를 하기 위해서는 3가지 과정을 거쳐야 함.
- 텍스트를 적절한 단위로 잘라 숫자형 아이디를 부여 (토큰화 tokenization)
- 토큰 아이디를 토큰 임베딩 층을 통해 여러 숫자의 집합인 토큰 임베딩으로 변환
- 위치 인코딩 층을 통해 토큰의 위치 정보를 담고 있는 위치 임베딩을 추가해 최종적으로 모델에 입력할 임베딩 만듦.
1. 토큰화
큰 단위 기준으로 토큰화할수록 텍스트의 의미가 잘 유지됨. but 사전의 크기가 커짐 (단어로 토큰화를 하는 경우 텍스트에 등장하는 단어의 수만큼 토큰 아이디가 필요하기 때문에 사전이 커진다, 또한 이전에 본 적이 없는 새로운 단어는 사전에 없기 때문에 처리하지 못하는 OOV(Out of Vocabulary)문제가 자주 발생)
작은 단위로 토큰화하는 경우 사전의 크기가 작고 OOV 문제를 줄일 수 있지만, 텍스트의 의미가 유지되지 않는다는 단점이 있음.
-> 최근에는 데이터에 등장하는 빈도에 따라 토큰화 단위를 결정하는 subword 토큰화 방식 3 을 사용