chapter 02-1 훈련 세트와 테스트 세트
지도 학습과 비지도 학습
- 지도 학습 알고리즘 -> 입력(데이터)과 타깃(정답)으로 이뤄진 훈련 데이터가 필요
- 입력 데이터만 있을 땐 비지도 학습 알고리즘 사용
- 강화학습 알고리즘 : 타깃이 아니라 알고리즘이 행동한 결과로 얻은 보상을 사용해 학습됨
+) 1장에서 사용한 k-최근접 이웃은 지도학습의 한 종류
머신러닝 알고리즘의 성능을 제대로 평가하려면 훈련 데이터와 평가에 사용할 데이터가 각각 달라야 한다 (또 다른 데이터를 준비하기 or 이미 준비된 데이터 중에서 일부를 떼어 내어 활용하기)
평가에 사용하는 데이터 : 테스트 세트
훈련에 사용되는 데이터 : 훈련 세트
훈련 세트와 테스트 세트
[29.0, 430.0]
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0]]
슬라이싱 연산을 사용하면 인덱스의 범위를 지정하여 원소를 여러 개 선택할 수 있음
ex) 0:5 -> 0~4까지의 5개 원소 선택
0:5 인 경우 0을 생략하고 쓸 수 있음
44: 마지막 인 경우 두번째 인덱스 생략할 수 있음
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0]]
[[12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
0.0- 테스트 세트에 빙어만 들어있고, 훈련 세트에 도미만 들어가 있으므로 순서대로 샘플링하면 한쪽으로 치우쳐져서 내가 원하는 값 못 얻음 (샘플링 편향)
특정 종류의 샘플이 과도하게 많은 샘플링 편향을 가지고 있다면 제대로 된 지도 학습 모델 만들 수 없음
넘파이
넘파이 : 파이썬의 대표적인 배열 라이브러리 (고차원의 배열을 조작할 수 있는 간편한 도구 제공)
1차원 배열 : 선
2차원 배열 : 면
3차원 배열 : 공간
시작이 왼쪽 위에서부터 시작
(49, 2)
[13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33
30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28
38]
[[ 26.3 290. ]
[ 29. 363. ]]
넘파이는 배열 인덱싱(array indexing) 기능 제공함
배열 인덱싱 : 1개의 인덱스가 아닌 여러 개의 인덱스로 한 번에 여러 개의 원소를 선택할 수 있음

두 번째 머신러닝 프로그램
1.0array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])마무리
지도 학습 : 입력과 카깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용함
비지도 학습 : 타깃 데이터가 없음. 무엇을 예측하는 것이 아니라 입력 데이터에서 어떤 특징을 찾는데 주로 활용
훈련 세트 : 모델을 훈련할 때 사용하는 데이터 / 클수록 좋음
테스트 세트 : 전체 데이터에서 20~30%를 테스트 세트로 사용하는 경우가 많음
numpy
- seed() : 난수를 생성하기 위한 정수 초깃값을 지정 (초깃값이 같으면 동일한 난수를 뽑을 수 있다)
- arange() : 일정한 간격의 정수 또는 실수를 만든다
{ 종료 숫자는 배열에 포함되지 않음 ex) arange(3) [0,1,2] arange(1,3) [1,2] arange(1,2,0.2)[1.,1.2,1.4,1.6,1.8] }
- shuffle() : 주어진 배열을 랜덤하게 섞음 (다차원 배열일 경우 첫 번째 축(행)에 대해서만 섞음
chapter 02-2 데이터 전처리
넘파이로 데이터 준비하기
튜플(tuple) : 리스트와 비슷, 리스트처럼 원소에 순서가 있지만 한 번 만들어진 튜플은 수정할 수 없다. 튜플을 사용하면 함수로 전달한 값이 바뀌지 않는다는 것을 믿을 수 있기 때문에 매개변수 값으로 많이 사용함
- column_stack : 행과 행으로 쌓아짐
- row_stack : 열과 열로 쌓아짐
- concatenate : 쭉 일열로 붙여
array([[1, 4],
[2, 5],
[3, 6]])[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]
사이킷런으로 훈련 세트와 테스트 세트 나누기
사이킷런은 머신러닝 모델을 위한 알고리즘 뿐만 아니라 다양한 유틸리티 도구도 제공함
train_test_split() : 전달되는 리스트나 배열을 비열에 맞게 훈련 세트와 테스트 세트로 나누어 줌
(36, 2) (13, 2)
(36,) (13,)
[1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
- stratify 매개변수에 타깃 데이터를 전달하면 클래스 비율에 맞게 데이터를 나눔
[0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1.]
수상한 도미 한마리
1.0[0.]


[[[ 25.4 242. ]
[ 15. 19.9]
[ 14.3 19.7]
[ 13. 12.2]
[ 12.2 12.2]]]
[[1. 0. 0. 0. 0.]]
[[ 92.00086956 130.48375378 130.73859415 138.32150953 138.39320793]]
- 이웃 샘플과의 거리를 봤을 때, 아무리봐도 몇 배 이상 차이나 보였는데 거리로는 92, 130 이런식으로 출력이 되었다 x축은 범위가 좁고(10-40), y축은 범위가 넓기 때문에(0-1000) y축으로 조금만 멀어져도 거리가 아주 큰 값으로 계산된다
기준을 맞춰라
x축의 범위를 동일하게 0-1000으로 맞추기 위해 x축 범위를 지정하기 위해 xlim() 함수 사용
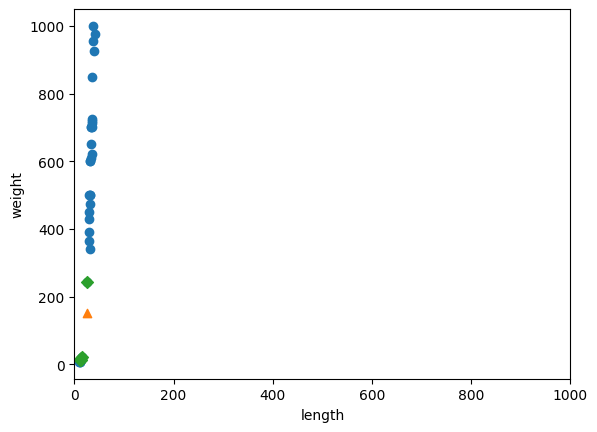
두 특성의 값이 놓인 범위가 매우 다르다. = 두 특성의 스케일(scale)이 다르다
알고리즘이 거리 기반일 때는 샘플 간의 거리에 영향을 많이 받으므로 제대로 사용하려면 특성값을 일정한 기준으로 맞춰야 함
스케일을 맞추는 작업 필요
특성마다 값의 스케일이 다르므로 평균과 표준편차는 각 특성별로 계산해야 한다 -> axis = 0으로 지정 (행을 따라 각 열의 통계 값을 계산함)
axis = 1로 하면 각 행을 따로따로 평균을 구함 (샘플마다 구해짐)
분산 : 데이터에서 평균을 뺀 값으 모두 제곱한 다음 평균을 냄
표준편차 : 분산의 제곱근 (데이터가 분산된 정도)
표준점수 : 각 데이터가 원점에서 몇 표준편차만큼 떨어져 있는지를 나타내는 값 (z점수, standard score) // 평균을 빼고 표준편차로 나누면 됨
[ 27.29722222 454.09722222] [ 9.98244253 323.29893931]
전처리 데이터로 모델 훈련하기


1.0[1.]

마무리
데이터 전처리 : 머신러닝 모델에 훈련 데이터를 주입하기 전에 가공하는 단계 표준점수 : 특성의 평균을 빼고 표준편차로 나눈다 브로드캐스팅 : 크기가 다른 넘파일 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능
scikit-learn
- train_test_split() : 훈련 데이터를 훈련 세트와 테스트 세트로 나누는 함수
- kneighbors() : 입력한 데이터에 가장 가까운 이웃을 찾아 거리와 이웃 샘플의 인덱스를 반환
https://github.com/minju00/ml/blob/5d2f0f78cb3210009250eccfe012a35333d56b37/ml_alone_Chapter_2.ipynb
'공부기록 > 머신러닝' 카테고리의 다른 글
| 혼자 공부하는 머신러닝+딥러닝 chapter 01 (1) | 2023.07.13 |
|---|
